
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Linux
- data structure
- Java
- Pipelining
- CSS
- web
- for
- javascript
- system
- DATAPATH
- Class
- mysql
- function
- instruction
- github
- html
- php
- openai
- control
- Algorithm
- computer
- python
- DS
- DB
- XML
- Rag
- architecture
- react
- AI
- MIPS
- Today
- Total
YYYEJI
[MAC] 키워드 검색(Keyword Search)을 기반으로 한 RAG 살펴보기 본문
RAG는 사용자의 질문을 검색기로 찾은 문서를 LLM이 답변을 생성해서 유저에게 보여줍니다.
이때 사용하는 검색기!!에 다양한 종류가 있습니다!
1) 의미론적 검색(Semantic Search)
[MAC] 의미론적 검색(Semantic Search)을 기반으로 한 RAG 살펴보기
RAG는 사용자의 질문을 검색기로 찾은 문서를 LLM이 답변을 생성해서 유저에게 보여줍니다.이때 사용하는 검색기!!에 다양한 종류가 있습니다! 1) 의미론적 검색(Semantic Search)2) 키워드 검색 (Keyword
yyyeji.tistory.com
2) 키워드 검색 (Keyword Search)
3) 하이브리드 검색 (Hybrid Search)
[MAC] 하이브리드 검색(Hybrid Search)을 기반으로 한 RAG 살펴보기
RAG는 사용자의 질문을 검색기로 찾은 문서를 LLM이 답변을 생성해서 유저에게 보여줍니다.이때 사용하는 검색기!!에 다양한 종류가 있습니다! 1) 의미론적 검색(Semantic Search)2) 키워드 검색 (Keyword
yyyeji.tistory.com
지금 이 글에서는 키워드 검색을 기반으로 한 RAG 검색기 코드를 살펴볼 예정입니다!
키워드 검색(Keyword Search)는
* 키워드 검색은 BM25 등 전통적 알고리즘 기반의 단어 매칭 방식이며,
정확한 단어/구문 매친에 강점이 있으며 계산 효율성이 우수합니다
* 직접적인 키워드 검색에는 효과적이나 의미적 연관성 파악에는 제한적이지만,
구현이 단순하고 처리 속도가 빠르다는 장점이 존재합니다.
여기서 BM25란????
BM25는 문서 검색 알고리즘이에요!
내 질문(쿼리)과 문서가 얼마나 관련 있는지를 점수로 계산해 주는 방식인데요!!
TF(Term Frequency) → 단어가 문서에 많이 나올수록 점수 ↑
IDF(Inverse Document Frequency) → 모든 문서에 흔히 나오는 단어는 점수 ↓
문장 길이 보정 → 문서가 길어서 단어가 많이 들어가는 경우 점수 조정
즉, 단어 중요도 + 등장 빈도 + 문장 길이 조정에 맞춰
문서와 쿼리의 관련성 점수를 계산하는 방식이에요!
키워드 검색을 위해서 BM25 검색기를 생성해야 돼요!
# 벡터 저장소에 저정한 문서 객체를 로드하여 확인
chroma_db.get().keys()
# BM25 검색기 생성을 위해 문서 객체를 로드
chroma_db.get()['documents'] # documents만 원본데이터가 보임
documents = chroma_db.get()['documents']
metadatas = chroma_db.get()['metadatas']
# Document 객체로 변환
from langchain_core.documents import Document
docs = [Document(page_content=page_content, metadata=metadata) for page_content, metadata in zip(documents, metadatas)]Chroma의 .get() 함수는 딕셔너리를 반환하고,
.key()는 'ids', 'embeddings', 'documents', 'metadatas'를 보여줍니다!
documents → 원래 page_content 문자열 목록이며,
metadatas → 문서별 메타데이터 딕셔너리 목록입니다.
docs 파일에 문자열과 메타데이터를 짝지어서 document 객체를 따로 생성해주면서,
BM25 검색기를 위한 리스트를 만들어주었습니다.
from langchain_community.retrievers import BM25Retriever
# BM25 검색기 생성 (retriever 객체 생성)
bm25_retriever = BM25Retriever.from_documents(docs)
# BM25 검색기를 사용하여 검색
query = "리비안은 언제 사업을 시작했나요?"
retriever_docs = bm25_retriever.invoke(query)BM25Retriever.from_documents() 안에 위에서 만든 docs(Document 객체 리스트)를 입력하여,
내부적으로 단어 토큰화를 시켰고, BM25 전수 계산을 위한 준비를 완료했습니다!
.invoke() 함수 안에 쿼리를 넣어 점수를 계산합니다!
(BM25는 벡터 임베딩이 아니라 "단어 매칭" 기반이라서 리비안이라는 단어가 그대로 있어야 높은 점수가 나옵니다)
(형태소 분석은 하지 않으면 'rivian' 같은 표기나 유사 단어는 찾지 못 한다고 해요 ㅠㅠ)
print("Query:", query)
print("="*200)
# '리비안'이라는 단어가 있을 시에만 검색 가능 (유사한 단어는 검색 X)
for doc in retriever_docs:
print(doc.page_content)
print("-"*200)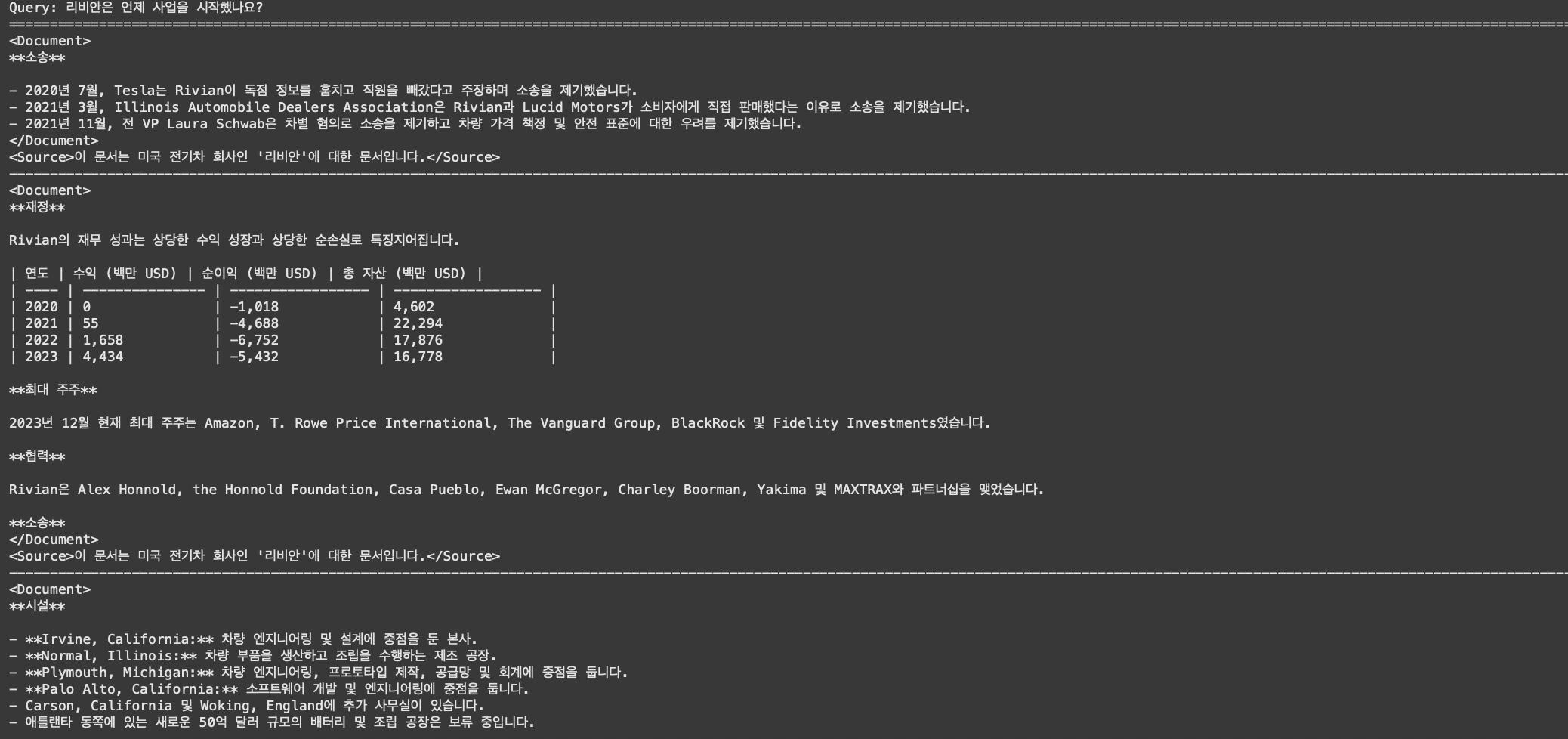
위에 코드를 통해 출력을 하면 이러한 결과를 얻어볼 수 있어요!!
지금까지
데이터 준비
↓
임베딩 생성
↓
벡터DB 저장
↓
로드
↓
벡터 검색
↓
BM25 검색
까지 살펴보았는데요
어떠셨나요?

'인공지능 챗봇' 카테고리의 다른 글
| [MAC] 재순위화(Re-rank) 기법 Cross-Encoder 모델과 LLMListwise 모델 비교하기 (4) | 2025.08.07 |
|---|---|
| [MAC] 하이브리드 검색(Hybrid Search)을 기반으로 한 RAG 살펴보기 (4) | 2025.08.06 |
| [MAC] 의미론적 검색(Semantic Search)을 기반으로 한 RAG 살펴보기 (4) | 2025.08.06 |
| [MAC] Naive RAG 구현 코드 구현하기 (13) | 2025.08.05 |
| [MAC] 벡터 저장소 기반 RAG 검색기 사용하기 (6) | 2025.08.05 |



